(사)한국인지과학산업협회 인지기술 튜토리얼 17-2
딥러닝 강화학습
2017년 5월 19일(금)
*본 튜토리얼은 부득이한 사정으로 19일 하루만 개최하게 되었습니다*
대전 KAIST IT 융합빌딩(N1) 다목적홀
초대의 글
강화학습은 인공지능 에이전트가 스스로 환경과 상호작용하며 사람이 정해준 정답 없이도 학습이 가능해 로봇의 컨트롤, 게임의 자동 플레이 등에 활발히 이용되고 있습니다. 또한 딥 러닝을 강화학습에 적용함으로써 최근 강화학습의 성능과 이용 가능성이 크게 향상되어 2016년에는 딥마인드의 강화학습 알고리즘인 알파고가 이세돌 9단과의 바둑 대국에서 승리를 거두는 등 발전이 두드러지고 있습니다. 본 튜토리얼에서는 강화학습의 기본 개념과 대표적인 학습 알고리즘, 딥 러닝을 접목한 딥 강화학습의 대표적인 모델 및 최신 연구 성과를 소개하고 기본적인 딥 강화학습 모델의 구현 실습을 진행하고자 하니 여러분의 많은 관심과 참여 부탁드립니다.
한국인지과학산업협회 회장
장 병 탁
개 요
- 목 적
- 딥러닝 실습에 대한 이해와 기술의 획득
- 진행 방식
- 다양한 실습과 데모가 포함된 튜토리얼
- 참석자는 각자 노트북 지참
- 실습을 위한 S/W 툴은 미리 다운로드 및 설치 권장 (추후 공지 예정)
- 참석 대상
- 딥러닝 실습에 관심 있는 기업체 연구원/대학원생
- 딥러닝 실습 관련 제품을 연구/개발하는 기업체연구자
- 딥러닝 실습의 인지기술/산업 응용에 관심 있는 연구자
- 인공지능/기계학습/인지컴퓨팅/빅데이터 분야의 연구자
프로그램
| 시 간 | 딥러닝 튜토리얼 : 강화학습 |
|
| 08:30~09:00 | 등 록 | 09:00~10:00 |
Reinforcement Learning의 동향 소개 이종호 부소장 (인지지능연구소) |
| 10:00~12:00 |
Reinforcement Learning 기초이론 곽동현 연구원(서울대학교) |
|
| 12:00~13:00 | 점심시간 | |
| 13:00~15:00 |
Reinforcement Learning과 최신 모델 최진영 연구원(서울대학교) |
|
| 15:00~15:30 | Coffe Break | |
| 15:30~17:30 |
Reinforcement Learning 오픈소스 실습 이범진 연구원 (서울대학교) |
|
프로그램 소개
- 강화학습 기초이론
-

이종호 부소장 (인지지능연구소)
-
강화 학습을 통해 변화하는 환경에 대응하여 학습하는 방법에 대한 소개와 함께, Deep learning과 강화 학습의 결합을 통한 인공지능 기법에 대해 개관하면서, OpenAI Gym 소개, TD Lambda, Policy Gradient, Deep Q learning 기법에 대한 개념과 동향을 소개한다.
-
(현) 한국인지과학산업협회 부설 인지지능연구소 부소장
(전) 삼성전자/종합기술원 수석연구원 -
Reinforcement Learning, Inverse Reinforcement Learning, Multi-Objective Reinforcement Learning
-
- TensorFlow 딥러닝 실습

곽동현 연구원 (서울대학교)
-
강화학습은 생명체의 의사결정 과정을 수학적으로 모델링하고, 이를 학습하기 위한 알고리즘이다. 강화학습을 이해하기 위해서는 먼저 MDP라는 도구를 활용해 문제를 정의하는 방법부터 이해해야 한다. 본 강의에서는 이러한 수학적인 도구를 최대한 쉽고 직관적으로 이해하는 것을 목표로 한다.
-
(현) 서울대학교 컴퓨터공학부 석박사통합과정
(전) 주식회사 Sagamore Studio 창업-CTO -
Deep Learning, Reinforcement Learning, Imitation Learning
- Deep Reinforcement Learning과 최신 모델

최진영 연구원 (서울대학교)
-
Deep learning을 Reinforcement learning에 적용한 Deep Reinforcement Learning은 게임, 로봇 컨트롤 등의 다양한 과제에서 인간을 넘어서는 성능을 보여주고 있다. 본 튜토리얼에서는 가장 널리 사용되는 Deep Reinforcement Learning 모델인 Deep Q Network와 A3C 등의 작동 원리를 설명하고 이를 기반으로 한 최신 연구 성과에 대해 소개한다.
-
(현)서울대학교 인지과학협동과정 석사과정
-
Deep Learning, Cognitive Science, Reinforcement Learning
- Reinforcement Learning 오픈소스 실습

이범진 연구원 (서울대학교)
-
OpenAI는 강화학습에 필수적인 실험환경을 제공해주는 오픈소스 Toolkit이다. 기초적인 Cartpole환경에서부터 Atari 그리고 3D 게임환경까지 제공하는 OpenAI는 개발자들이 개발한 강화학습 알고리즘을 직접 적용하고 동시에 전세계 개발자들과 알고리즘 성능을 비교함으로써 더욱 강력한 알고리즘 개발이 가능토록 해준다. 본 강의에서는 OpenAI를 기반으로 강화학습과 딥 러닝을 접목하여 에이전트의 성능을 비약적으로 향상시킨 딥강화학습 모델의 예인 딥큐넷(DQN)과 Policy Gradient등의 핵심적인 알고리즘 전반을 실습한다. OpenAI와 Tensorflow를 같이 사용하여 프로그래밍하고 알고리즘을 시뮬레이션하여 이론을 입체적으로 이해할 수 있도록 돕는다.
-
(현) 서울대학교 컴퓨터공학부 석박사통합과정 수료, 서울대학교 강좌 ‘데이터마이닝 그리고 정보검색’ 강의 조교
-
인공지능, 기계학습, Deep Reinforcement Learning, Cognitive Robotics, Developmental Robotics
- 등록비 (19일 결제바로가기)
-
한국인지과학산업협회 유료 가입 회원사(2명까지) ☞ 협회 가입방법
무료 등록 예정자 (2명 까지)의 참가신청서를 작성하여 event.nacsi@gmail.com로 보내주시기 바랍니다.
-
학생 등록 20만원
일반 등록 40만원
-
- 등록 방법
-
카드 결제 또는 온라인 입금 후 확인 메일 발송
-
카드 결제 사이트 (클릭)에서 결제 후 참가신청서를 작성하여 event.nacsi@gmail.com로 보내주시기 바랍니다. (참가신청서 파일 다운로드

 )
)
-
아래의 계좌에 등록비를 입금하신 후 참가신청서를 작성하여 event.nacsi@gmail.com로 보내주시기 바랍니다. (참가신청서 파일 다운로드
)
- 은행: 농협은행
- 예금주: (사)한국인지과학산업협회
- 계좌번호: 301-0157-1285-21
-
한국인지과학산업협회 사무국
T. 070-4106-1005, event.nacsi@gmail.com
-
- 등록 혜택 안내
- 모든 등록자분들께 "인지기술튜토리얼 참가확인증"을 발급 해 드립니다.
- 강의 자료는 등록자에 한하여 online (by e-mail)으로 배포 될 예정입니다.
참가신청 안내
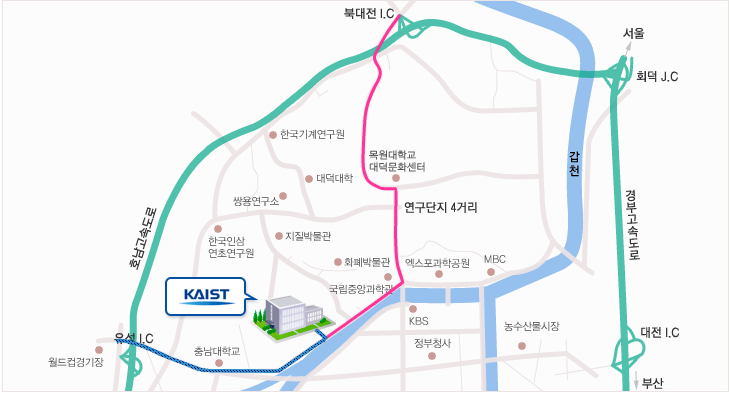
오시는 길
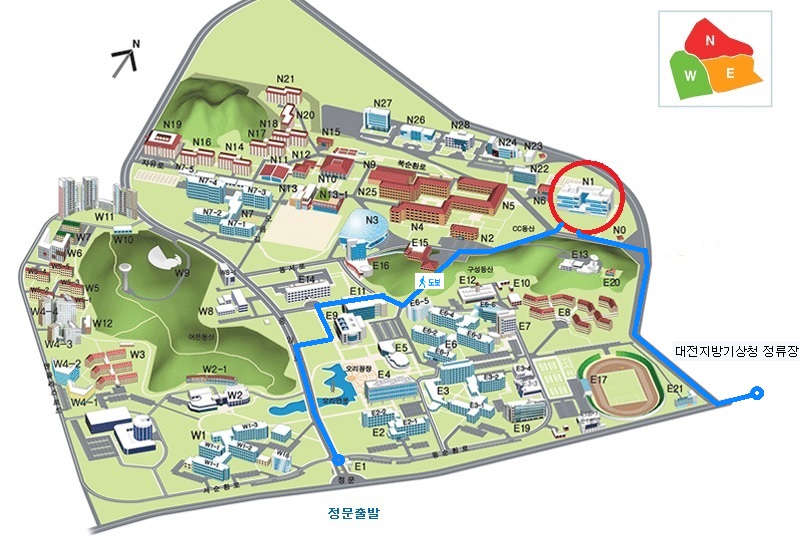
대전 KAIST IT 융합빌딩(N1) 다목적홀
TEL 070-4106-1005
대전역에서 지하철 이용시
대전역에서 지하철 (약 30분): 대전역 → 월평역(KAIST역)
월평(KAIST)역 출발 시간표: 월평역 출발 → KAIST 운행
08:28(출근버스), 09:40, 10:40, 11:40, 13:40, 14:40, 15:40, 16:40, 17:40
승차 장소: 월평역 3번 출구 → 50m → 버스 정류장 옆 → KAIST 정문 하차 → KAIST IT 융합빌딩(N1) 다목적홀
고속버스 이용시
정부대전청사 시외버스터미널 (소요시간 : 약 20분) 택시(10분)
정부대전청사서문정류장에서 604번 승차 → KAIST 동문 건너편(원자력안전기술원정류장) 하차
유성시외버스터미널 (소요시간 : 약 35분)택시(10분)
터미널 길건너 유성시외버스정류장에서 121번버스 승차 → KAIST 정문 하차 → KAIST IT 융합빌딩(N1) 다목적홀
KAIST 약도
 <교통편>
< 안내도>
<셔틀>
<교통편>
< 안내도>
<셔틀>